voidVariationalInference(int N, int K, VectorXi X, int MAXITER, int seed){
// function to do Variational Inference// inputs:// N: the number of data points// K: the number of clusters// X: the data// MAXITER: the maximum number of iterations// seed: the random seed value// set random engine with the random seed valuestd::default_random_engine engine(seed);
// set the output filestd::ofstream samples("VI-samples.csv");
// set the headers in the filefor (int k =0; k < K; k++) samples <<"a."<< k <<",";
for (int k =0; k < K; k++) samples <<"b."<< k <<",";
for (int k =0; k < K; k++) samples <<"lambda."<< k <<",";
for (int k =0; k < K; k++) samples <<"alpha."<< k <<",";
for (int k =0; k < K; k++) samples <<"pi."<< k <<",";
for (int n =0; n < N; n++) samples <<"s."<< n <<",";
samples <<"ELBO"<<std::endl;
// set variables VectorXd a; // the shape parameter VectorXd a_hat; // the modified shape parameter VectorXd b; // the rate parameter VectorXd b_hat; // the modified rate parameter VectorXd alpha; // the concentration parameter VectorXd alpha_hat; // the modified concentration parameter VectorXd lambda; // the rate parameter VectorXd pi; // the mixing parameter VectorXd s; // the latent variableMatrixXd expt_S(N,K); // E[S]MatrixXd ln_expt_S(N,K); // ln E[S]double ELBO; // ELBO// set initial values a = VectorXd::Constant(K,1,uniform_rng(0.1,2.0,engine));
b = VectorXd::Constant(K,1,uniform_rng(0.005,0.05,engine));
alpha = VectorXd::Constant(K,1,uniform_rng(10.0,200.0,engine));
pi = dirichlet_rng(alpha,engine);
s = VectorXd::Zero(N,1); // initialize s with zeros expt_S = MatrixXd::Zero(N,K); // initialize expt_S with zerosfor (int n =0; n < N; n++) {
s(n) = categorical_rng(pi,engine);
expt_S(n,s(n)-1) =1;
}
a_hat = a + expt_S.transpose() * X;
b_hat = b + expt_S.colwise().sum().transpose();
alpha_hat = alpha + expt_S.colwise().sum().transpose();
// samplingfor (int i =1; i <= MAXITER; i++) {
// sample s VectorXd expt_lambda = a_hat.array() / b_hat.array();
VectorXd expt_ln_lambda = stan::math::digamma(a_hat.array()) - stan::math::log(b_hat.array());
VectorXd expt_ln_pi = stan::math::digamma(alpha_hat.array()) - stan::math::digamma(stan::math::sum(alpha_hat.array()));
for (int n =0; n < N; n++) {
ln_expt_S.row(n) = X(n) * expt_ln_lambda - expt_lambda + expt_ln_pi;
ln_expt_S.row(n) -= rep_row_vector(log_sum_exp(ln_expt_S.row(n)), K);
expt_S.row(n) =exp(ln_expt_S.row(n));
s(n) = categorical_rng(expt_S.row(n), engine);
}
// sample lambda a_hat = a + expt_S.transpose() * X;
b_hat = b + expt_S.colwise().sum().transpose();
lambda = to_vector(gamma_rng(a_hat,b_hat,engine));
// sample pi alpha_hat = alpha + expt_S.colwise().sum().transpose();
pi = dirichlet_rng(alpha_hat,engine);
// calc ELBO ELBO = calc_ELBO(N, K, X, a, b, alpha, a_hat, b_hat, alpha_hat);
// outputfor (int k =0; k < K; k++) samples << a_hat(k) <<",";
for (int k =0; k < K; k++) samples << b_hat(k) <<",";
for (int k =0; k < K; k++) samples << lambda(k) <<",";
for (int k =0; k < K; k++) samples << alpha_hat(k) <<",";
for (int k =0; k < K; k++) samples << pi(k) <<",";
for (int n =0; n < N; n++) samples << s(n) <<",";
samples << ELBO <<std::endl;
}
}
intmain(int argc, char*argv[]){
// get inputs 1 ~ 4std::string method = argv[1];
int N = atoi(argv[2]);
int K = atoi(argv[3]);
int seed = atoi(argv[4]);
if (method =="data") {
「# calculate EAP for lambda and sort them to control the order of clusters」における処理の意味については
ギブスサンプリングの記事で説明してあるので、興味のある方は覗いてみてください(よりきれいな可視化のための操作で、省略しても問題のないものです)。
# A tibble: 2 x 7
k lambda .lower .upper .width .point .interval
<int> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1143.943.344.50.95 mean qi
2277.176.577.80.95 mean qi
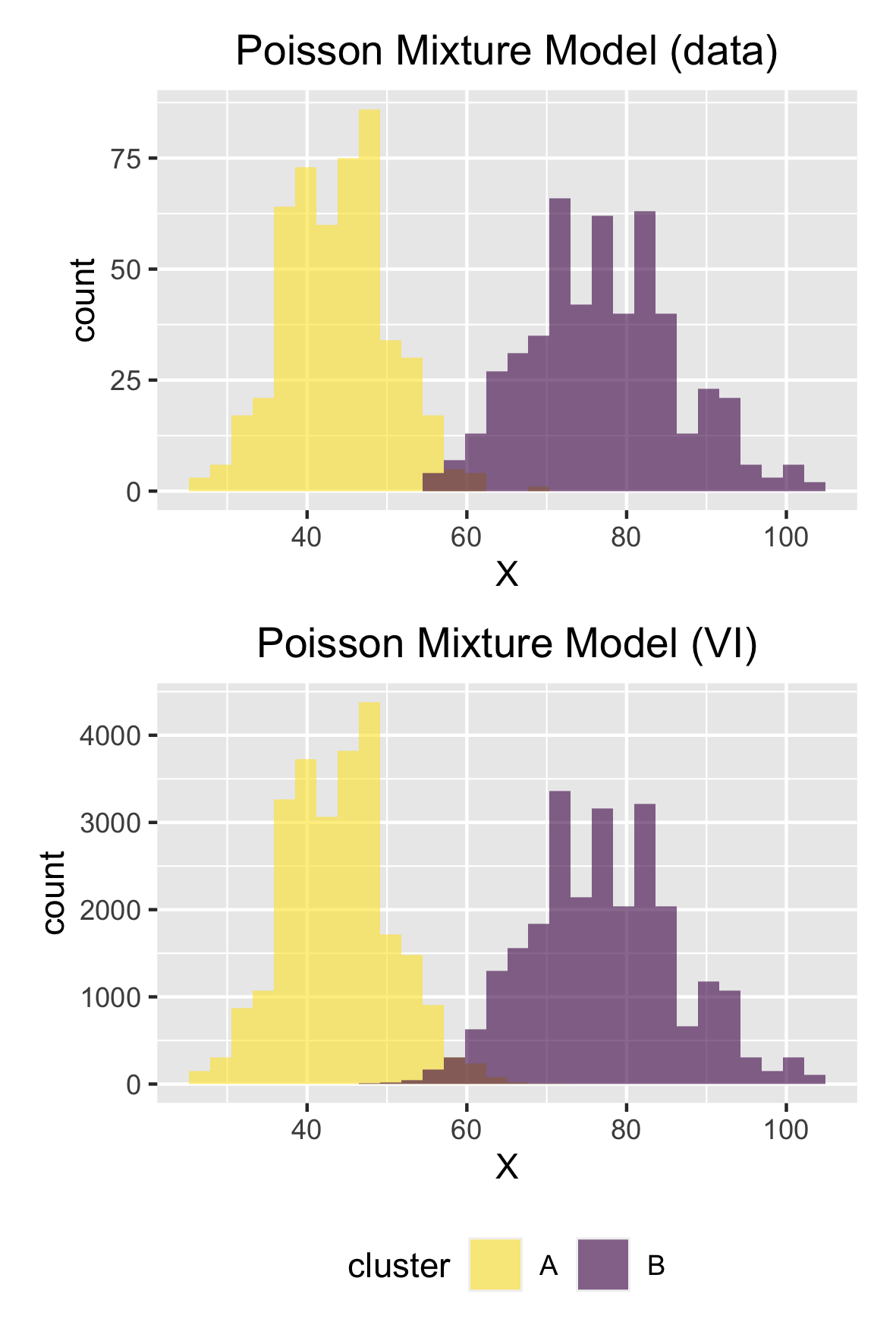
実際の値は 44, 77 ですから、問題なく推論できていますね。
同様に のサンプルからその平均と、95%信頼区間を算出してみます。
233234235236237
# Estimated pi
VI$pi%>%filter(iteration >= MAXITER /2) %>%group_by(k) %>%mean_qi(pi)
# A tibble: 2 x 7
k pi .lower .upper .width .point .interval
<int> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
110.5010.4780.5250.95 mean qi
220.4990.4750.5220.95 mean qi