voidCollapsedGibbsSampling(int N, int K, VectorXi X, int MAXITER, int seed) {
// function to do Collapsed Gibbs Sampling
// inputs:
// N: the number of data points
// K: the number of clusters
// X: the data
// MAXITER: the maximum number of iterations
// seed: the random seed value
// set random engine with the random seed value
std::default_random_engine engine(seed);
// set the output file
std::ofstream samples("CGS-samples.csv");
// set the headers in the file
for (int k =0; k < K; k++) samples <<"a."<< k <<",";
for (int k =0; k < K; k++) samples <<"b."<< k <<",";
for (int k =0; k < K; k++) samples <<"alpha."<< k <<",";
for (int n =0; n < N; n++) samples <<"s."<< n <<",";
samples <<"ELBO"<< std::endl;
// set variables
VectorXd a; // the shape parameter
VectorXd a_hat; // the modified shape parameter
VectorXd b; // the rate parameter
VectorXd b_hat; // the modified rate parameter
VectorXd alpha; // the concentration parameter
VectorXd alpha_hat; // the modified concentration parameter
VectorXd s; // the latent variable
MatrixXd S(N,K); // the latent variable (one-hot-labeling)
VectorXd sX_csum; // represents the sum_{n}^{N}(s_{n,k} * x_{n})
VectorXd S_csum; // represents the sum_{n}^{n}(s_{n,k})
VectorXd ln_lkh; // represents (log-) likelihood at Eq. (4.76)
double ELBO; // ELBO
// set initial values
a = VectorXd::Constant(K,1,uniform_rng(0.1,2.0,engine));
b = VectorXd::Constant(K,1,uniform_rng(0.005,0.05,engine));
alpha = VectorXd::Constant(K,1,uniform_rng(10.0,200.0,engine));
s = VectorXd::Zero(N,1); // initialize s with zeros
S = MatrixXi::Zero(N,K); // initialize S with zeros
for (int n =0; n < N; n++) {
s(n) = categorical_rng(rep_vector(1.0/K,K),engine);
S(n,s(n)-1) =1;
}
// calc a_hat, b_hat, and alpha_hat
sX_csum = (S.array() * X.rowwise().replicate(K).array()).matrix().colwise().sum();
S_csum = S.colwise().sum();
a_hat = a + sX_csum;
b_hat = b + S_csum;
alpha_hat = alpha + S_csum;
// sampling
for (int i =1; i <= MAXITER; i++) {
for (int n =0; n < N; n++) {
// remove components related to x_{n}
a_hat -= S.row(n) * X(n);
b_hat -= S.row(n);
alpha_hat -= S.row(n);
// calc ln_lkh
ln_lkh = VectorXd::Zero(K); // initialize ln_lkh with zeros
for (int k =0; k < K; k++) {
ln_lkh(k) = neg_binomial_lpmf(X(n),a_hat(k),b_hat(k)) + stan::math::log(alpha_hat(k));
}
// sample s
S = MatrixXi::Zero(N,K); // initialize S with zeros
ln_lkh -= rep_vector(log_sum_exp(ln_lkh),K);
s(n) = categorical_rng(stan::math::exp(ln_lkh),engine);
S(n,s(n)-1) =1;
// add components related to x_{n}
a_hat += S.row(n) * X(n);
b_hat += S.row(n);
alpha_hat += S.row(n);
}
// calc ELBO
ELBO = calc_ELBO(N, K, X, a, b, alpha, a_hat, b_hat, alpha_hat);
// output
for (int k =0; k < K; k++) samples << a_hat(k) <<",";
for (int k =0; k < K; k++) samples << b_hat(k) <<",";
for (int k =0; k < K; k++) samples << alpha_hat(k) <<",";
for (int n =0; n < N; n++) samples << s(n) <<",";
samples << ELBO << std::endl;
}
}
intmain(int argc, char*argv[]) {
// get inputs 1 ~ 4
std::string method = argv[1];
int N = atoi(argv[2]);
int K = atoi(argv[3]);
int seed = atoi(argv[4]);
if (method =="data") {
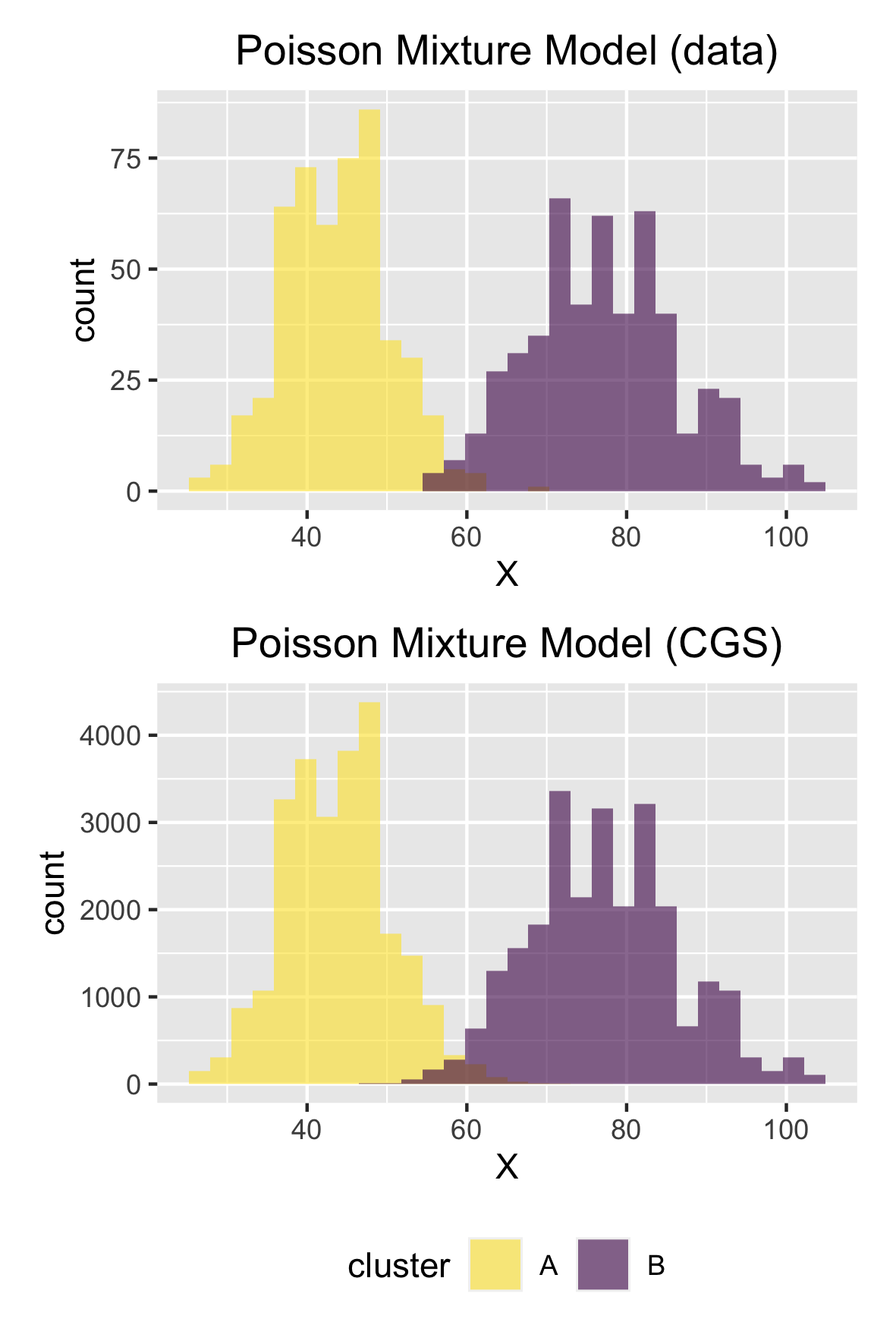
# pull s samples
CGS$s <-
CGS$samples %>%select(iteration, starts_with("s.")) %>%pivot_longer(cols =starts_with("s."),
names_to ="n",
names_pattern ="s.([0-9]+)",
names_transform =list(n = as.integer),
values_to ="s",
values_transform =list(s = as.integer)) %>%mutate(X = demo_data$X[n+1])
# calculate MLE for lambda and sort them to control the order of clusters
sorted_lambda <-
CGS$s %>%group_by(s) %>%summarise(lambda_MLE =sum(X) /n(), .groups ="drop") %>%pull(lambda_MLE) %>%sort.int(index.return =TRUE)
map_s <-1:K
names(map_s) <- sorted_lambda$ix
# recode cluster indices
CGS$s <-
CGS$s %>%mutate(s =recode(s, !!!map_s))
「# calculate MLE for lambda and sort them to control the order of clusters」における処理の意味については
ギブスサンプリングの記事で説明してあるので、興味のある方は覗いてみてください(よりきれいな可視化のための操作で、省略しても問題のないものです)。