voidGibbsSampling(int N, int K, VectorXi X, int MAXITER, int seed){
// function to do Gibbs Sampling// inputs:// N: the number of data points// K: the number of clusters// X: the data// MAXITER: the maximum number of iterations// seed: the random seed value// set random engine with the random seed valuestd::default_random_engine engine(seed);
// set the output filestd::ofstream samples("GS-samples.csv");
// set the headers in the filefor (int k =0; k < K; k++) samples <<"a."<< k <<",";
for (int k =0; k < K; k++) samples <<"b."<< k <<",";
for (int k =0; k < K; k++) samples <<"lambda."<< k <<",";
for (int k =0; k < K; k++) samples <<"alpha."<< k <<",";
for (int k =0; k < K; k++) samples <<"pi."<< k <<",";
for (int n =0; n < N; n++) samples <<"s."<< n <<",";
samples <<"ELBO"<<std::endl;
// set variables VectorXd a; // the shape parameter VectorXd a_hat; // the modified shape parameter VectorXd b; // the rate parameter VectorXd b_hat; // the modified rate parameter VectorXd alpha; // the concentration parameter VectorXd alpha_hat; // the modified concentration parameter VectorXd lambda; // the rate parameter VectorXd pi; // the mixing parameterMatrixXd eta(N,K); // the temporal parameter to sample s VectorXi s; // the latent variableMatrixXi S(N,K); // the latent variable (one-hot-labeling)double ELBO; // ELBO// set initial values a = VectorXd::Constant(K,1,uniform_rng(0.1,2.0,engine));
b = VectorXd::Constant(K,1,uniform_rng(0.005,0.05,engine));
lambda = to_vector(gamma_rng(a,b,engine));
alpha = VectorXd::Constant(K,1,uniform_rng(10.0,200.0,engine));
pi = dirichlet_rng(alpha,engine);
// samplingfor (int i =1; i <= MAXITER; i++) {
// sample s and S s = VectorXi::Zero(N,1); // initialize s with zeros S = MatrixXi::Zero(N,K); // initialize S with zerosfor (int n =0; n < N; n++) {
eta.row(n) = X(n) *log(lambda) - lambda +log(pi);
eta.row(n) -= rep_row_vector(log_sum_exp(eta.row(n)),K);
s(n) = categorical_rng(exp(eta.row(n)), engine);
S(n,s(n)-1) =1;
}
// sample lambda a_hat = a + S.transpose() * X;
b_hat = b + S.colwise().sum().transpose();
lambda = to_vector(gamma_rng(a_hat,b_hat,engine));
// sample pi alpha_hat = alpha + S.colwise().sum().transpose();
pi = dirichlet_rng(alpha_hat,engine);
// calc ELBO ELBO = calc_ELBO(N, K, X, a, b, alpha, a_hat, b_hat, alpha_hat);
// outputfor (int k =0; k < K; k++) samples << a_hat(k) <<",";
for (int k =0; k < K; k++) samples << b_hat(k) <<",";
for (int k =0; k < K; k++) samples << lambda(k) <<",";
for (int k =0; k < K; k++) samples << alpha_hat(k) <<",";
for (int k =0; k < K; k++) samples << pi(k) <<",";
for (int n =0; n < N; n++) samples << s(n) <<",";
samples << ELBO <<std::endl;
}
}
intmain(int argc, char*argv[]){
// get inputs 1 ~ 4std::string method = argv[1];
int N = atoi(argv[2]);
int K = atoi(argv[3]);
int seed = atoi(argv[4]);
if (method =="data") {
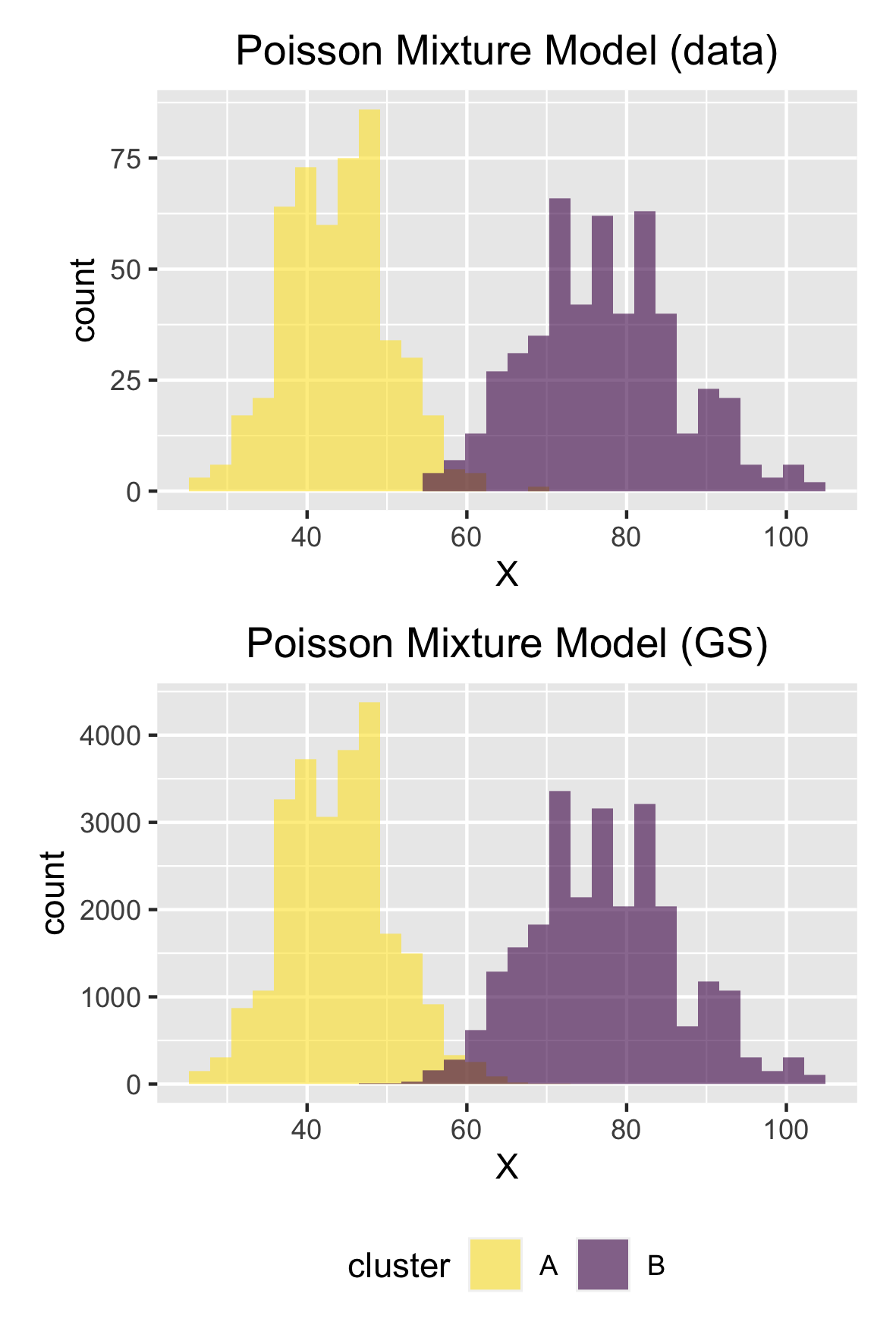
ただ、 としてパラメータが渡されているデモデータと比較する上では、可視化の際などに色が反転してしまって見づらくなってしまうので、「# calculate EAP for lambda and sort them to control the order of clusters」の処理では、値を昇順に並び替えるように添字を振り直しています(対応してデモデータを生成するさいには常に昇順でパラメータを与えてやる必要があります)。
# A tibble: 2 x 7
k lambda .lower .upper .width .point .interval
<int> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1143.943.444.40.95 mean qi
2277.276.578.10.95 mean qi
実際の値は 44, 77 ですから、問題なく推論できていますね。
同様に のサンプルからその平均と、95%信頼区間を算出してみます。
135136137138139
# Estimated pi
GS$pi%>%filter(iteration >= MAXITER /2) %>%group_by(k) %>%mean_qi(pi)
# A tibble: 2 x 7
k pi .lower .upper .width .point .interval
<int> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
110.5020.4790.5260.95 mean qi
220.4980.4740.5210.95 mean qi